
Платформа наблюдаемости & непрерывной аналитики операционных данных
Развивайте бизнес, а не системы мониторинга
Повышает производительность и снижает затраты на IT

Сводит к минимуму простои и сбои


Позволяет легко масштабировать решения
Sage o11y выбирают, когда компании нужно расти, а старая архитектура уже не справляется
Sage o11y — единый высококонтекстный инструмент, который помогает досконально разбираться, как работает IT-инфраструктура и системы: от оборудования до приложений пользователей
Теряете много денег и ресурсов из-за простоев — ущерб сложно оценить. Не знаете, кто попал под влияние сбоя
Обеспечивает высокий уровень SLO/SLA-систем и сервисов, снижает MTTD/MTTR. Помогает развиваться, а не тушить пожары и позволяет отслеживать миллионы индикаторов (SLI)
Как помогает Sage o11y
Проблемы старой архитектуры


Сложно учесть и предугадать сбои в IT — они частые, вы узнаете о них по жалобам пользователей
Трудно подсчитать затраты на поддержку и развитие IT-инфраструктуры, потому что они непрозрачны
Показывает, где и как оптимизировать бизнес-процессы: собирает процесс в единое целое и анализирует его от начала до конца.
Позволяет отследить нагрузки и утилизацию ресурсов, чтобы понять эффективность затрат на инфраструктуру, выявить избыточные ресурсы и перенаправить бюджет на развитие
Позволяет отследить нагрузки и утилизацию ресурсов, чтобы понять эффективность затрат на инфраструктуру, выявить избыточные ресурсы и перенаправить бюджет на развитие
Сложно анализировать разрозненные данные и своевременно принимать решения
Развивает data-driven-культуру и демократизацию доступа к данным благодаря гибкой ролевой модели и простому, но функциональному языку запросов к данным
Производительность падает при внедрении и разработке ПО
Анализирует работу систем в реальном времени, помогает сразу понять, почему и в результате чего падает производительность.
Может предсказать сбои до того, как они станут проблемой
Может предсказать сбои до того, как они станут проблемой
Не знаете, сколько ресурсов тратите на эксплуатацию сервисов
Sage o11y содержит все метрики потребления, позволяет рассчитать время и стоимость простоя, выявить ресурсы, которые используются неоптимально
Сталкиваетесь с текучкой кадров из-за большой когнитивной нагрузки, вызванной множеством разрозненных инструментов
Освобождает сотрудников от рутины — их силы можно направить на другие сложные задачи
Ищете аналоги привычных систем, которые ушли с российского рынка: Splunk, New Relic, Dynatrace, Instana, Micro Focus, AppDynamics и других
Избавляет от зоопарка решений: Sage o11y — единый консолидированный инструмент.
Это центр истины, который делает взаимодействие отделов разработки, эксплуатации и бизнеса более эффективным
Это центр истины, который делает взаимодействие отделов разработки, эксплуатации и бизнеса более эффективным
Проблемы старой архитектуры
Sage o11y собирает, обрабатывает и с помощью AI анализирует данные из всех сервисов
В режиме реального времени. Это помогает сразу выявлять аномалии, своевременно реагировать и быстро устранять инциденты

Sage o11y помогает масштабироваться
— надежное решение для неструктурированных данных
— «горячее», «теплое» хранилище и «ледник» для долгосрочного хранения данных
* По результатам внутренних тестов Т-Банка.
Собственное хранилище SageDB в 12 раз эффективнее хранит данные, чем Elasticsearch *
Обработка свыше 350 ТБ данных в сутки
Обработка 30 млн уникальных временных рядов
Поток трейсинга свыше 1 ГБ/с
Структуру можно модернизировать под потребности компании. Платформа справляется с высокими нагрузками
Sage o11y использует
платформенный подход
платформенный подход
у аналитиков, инженеров и руководителей
в том числе с точки зрения законов о персональных данных
Доступ к данным есть у любых ролей в режиме self-service
Это эффективно и безопасно

2
Срок: 1–2 недели
Оцениваем проект
— рассчитываем емкость проекта и стоимость лицензий
— считаем, во сколько обойдутся сопутствующие услуги
— считаем, во сколько обойдутся сопутствующие услуги
3
Срок: 1 месяц
Тестируем инсталляцию
проверяем, как работает тестовая коммерческая инсталляция в контуре клиента на выделенных системах и сценариях
4
Срок: многолетнее сотрудничество
Внедряем Sage o11y
и масштабируем платформу в контуре организации
1
Срок: 1–2 недели
Начинаем с задачи
— обсуждаем цели и задачи
— обследуем процессы
— собираем данные
— обследуем процессы
— собираем данные
Как мы внедряем платформу Sage o11y
Сопровождаем процесс на всех этапах: от обсуждения целей до масштабирования платформы
Мы уже добились высоких результатов
на 95%
снизили количество сбоев в IT-инфраструктуре Т-Банка при ее четырехкратном росте

< 1 минуты
уходит, чтобы отреагировать на проблему клиента в экосистеме Т-Банка
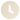
99,999%
SLA обеспечили АО «НСПК» — оператору платежной системы «Мир»




C помощью Sage o11y наблюдаются
C помощью Sage o11y наблюдаются
Условия передачи информации
Я даю согласие ООО «ТЦР», ОГРН 5167746308549, адрес 127287, г. Москва, ул. Хуторская 2-я, д. 38А, стр. 26, 4 этаж, помещение VIII, комната 10 на обработку всех моих персональных данных, имеющихся в распоряжении Центра Разработки, предоставленных мной Центру Разработки, в том числе указанных в заявке и/или иным образом полученных Центром Разработки, любыми способами, включая сбор, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (предоставление, доступ), обезличивание, блокирование, удаление, уничтожение, а также на вышеуказанную обработку иных моих персональных данных, полученных в результате их обработки, включая обработку третьими лицами, с целью:
· заключения с Центром Разработки договора;
· предоставления мне товаров, работ и услуг;
· создания информационных систем персональных данных Центра Разработки;
· заключения и исполнения договоров, где я являюсь стороной либо выгодоприобретателем или поручителем;
· а также в любых других целях, прямо или косвенно связанных с деятельностью Центра Разработки, и направления мне информации о новых продуктах и услугах Центра Разработки и/или его контрагентов.
· Я даю согласие контрагентам Центра Разработки на обработку всех моих персональных данных, имеющихся в распоряжении/доступе Центра Разработки и/или контрагентов Центра Разработки, в том числе с целью информирования меня об услугах контрагентов.
Указанное согласие дано на срок 15 лет, а в случае его отзыва обработка моих персональных данных должна быть прекращена Центром Разработки и/или третьими лицами и данные уничтожены при условии расторжения договора и полного погашения задолженности по договору в срок не позднее 1 (одного) года с даты прекращения действия договора.
Я даю согласие на получение мной и, если применимо, юридическим лицом, данные которого указаны в заявке, рассылки и рекламы по сетям электросвязи, включая подвижную радиотелефонную связь, от Центра Разработки и его аффилированных лиц, а также партнеров Центра Разработки.
Настоящим я даю согласие на получение данных в отношении юридического лица, единоличным исполнительным органом / уполномоченным представителем которого я являюсь и данные которого указаны в заявке, у третьих лиц, в том числе операторов фискальных данных и операторов электронного документооборота.
· заключения с Центром Разработки договора;
· предоставления мне товаров, работ и услуг;
· создания информационных систем персональных данных Центра Разработки;
· заключения и исполнения договоров, где я являюсь стороной либо выгодоприобретателем или поручителем;
· а также в любых других целях, прямо или косвенно связанных с деятельностью Центра Разработки, и направления мне информации о новых продуктах и услугах Центра Разработки и/или его контрагентов.
· Я даю согласие контрагентам Центра Разработки на обработку всех моих персональных данных, имеющихся в распоряжении/доступе Центра Разработки и/или контрагентов Центра Разработки, в том числе с целью информирования меня об услугах контрагентов.
Указанное согласие дано на срок 15 лет, а в случае его отзыва обработка моих персональных данных должна быть прекращена Центром Разработки и/или третьими лицами и данные уничтожены при условии расторжения договора и полного погашения задолженности по договору в срок не позднее 1 (одного) года с даты прекращения действия договора.
Я даю согласие на получение мной и, если применимо, юридическим лицом, данные которого указаны в заявке, рассылки и рекламы по сетям электросвязи, включая подвижную радиотелефонную связь, от Центра Разработки и его аффилированных лиц, а также партнеров Центра Разработки.
Настоящим я даю согласие на получение данных в отношении юридического лица, единоличным исполнительным органом / уполномоченным представителем которого я являюсь и данные которого указаны в заявке, у третьих лиц, в том числе операторов фискальных данных и операторов электронного документооборота.
Operational Intelligence — аналитика «на лету», подмножество анализа данных, направленное на улучшение операционной деятельности бизнеса
Observability с уровня ИТ-инфраструктуры до бизнес-процессов